
핵심 요약
구성 01
무엇이 실제로 바뀌었나
구성 02
가격과 접근 권한이 왜 핵심인가
구성 03
벤치마크는 어디까지 믿어야 하나
OpenAI GPT-5.5에서 실제로 달라진 것은 “새 모델이 나왔다”가 아니라, Codex와 ChatGPT에서 긴 코딩·리서치·문서 작업을 더 오래 끌고 가는 방식입니다. 하지만 실무자가 바로 결정해야 할 질문은 성능이 좋아졌다는 말이 아니라, 지금 내 비용과 권한 조건에서 쓸 만큼 이득이 있는지입니다.
이 글은 GPT-5.5를 지금 써야 하는지 판단하기 위해 네 가지만 분리합니다. 무엇이 달라졌는지, 누가 먼저 체감하는지, API와 Codex 비용·권한이 어떻게 다른지, 그리고 벤치마크 수치를 어디까지 믿어야 하는지입니다.
도입 판단 비교표
| 판단 축 | 지금 움직일 조건 | 보류할 조건 |
|---|---|---|
| Codex 작업 | 큰 코드베이스에서 구현·리팩터링·디버깅을 반복한다 | 짧은 코드 질문이나 단발성 답변이 대부분이다 |
| API 비용 | 출력 품질 향상으로 재시도와 검수 비용을 줄일 수 있다 | 출력 토큰이 많은 자동화인데 비용 상한이 빡빡하다 |
| 벤치마크 신뢰 | Terminal-Bench 2.0, SWE-Bench Pro 같은 작업형 지표가 내 업무와 닮았다 | 내 업무가 단순 요약, 짧은 Q&A, 저비용 대량 호출에 가깝다 |
가령 보안팀은 먼저 승인되지 않은 에이전트 목록을 찾고, 운영팀은 각 에이전트의 권한·로그·되돌리기 절차가 실제 장애 상황에서 작동하는지 확인해야 합니다.
무엇이 실제로 바뀌었나
OpenAI는 GPT-5.5를 2026년 4월 23일 공개하면서 agentic coding, computer use, knowledge work, scientific research를 핵심 영역으로 제시했습니다. 즉 변화의 중심은 “답을 더 잘한다”보다, 여러 단계의 작업을 계획하고 도구를 쓰고 검토하며 끝까지 진행하는 쪽입니다.
그래서 독자가 먼저 확인할 것은 모델명보다 작업 단위입니다. 문서 하나를 요약하는 정도라면 차이가 작을 수 있지만, 코드 수정과 테스트, 자료 조사와 문서화, 스프레드시트 생성처럼 여러 도구를 오가는 작업이라면 체감 차이가 커질 수 있습니다.
그래서 다음에는 가격과 접근 권한이 왜 핵심인가를 보면 판단이 더 쉬워집니다.
가격과 접근 권한이 왜 핵심인가
가격은 이번 글의 핵심입니다. OpenAI 발표 기준 Codex의 GPT-5.5는 Plus, Pro, Business, Enterprise, Edu, Go 플랜에서 400K context window로 제공됩니다. 반면 API는 gpt-5.5 기준 1M context window, 입력 100만 토큰당 5달러, 출력 100만 토큰당 30달러로 예고됐습니다.
하지만 API 자동화를 운영하는 팀은 출력 비용을 먼저 봐야 합니다. 예를 들어 리서치 보고서, 코드 리뷰, 긴 문서 생성처럼 출력이 길어지는 작업은 성능 향상이 있어도 비용이 빠르게 커질 수 있습니다. 그래서 “좋은 모델인가”보다 “재시도와 검수 시간을 줄여 총비용을 낮추는가”가 더 정확한 질문입니다.
그래서 다음에는 벤치마크는 어디까지 믿어야 하나를 보면 판단이 더 쉬워집니다.
벤치마크는 어디까지 믿어야 하나
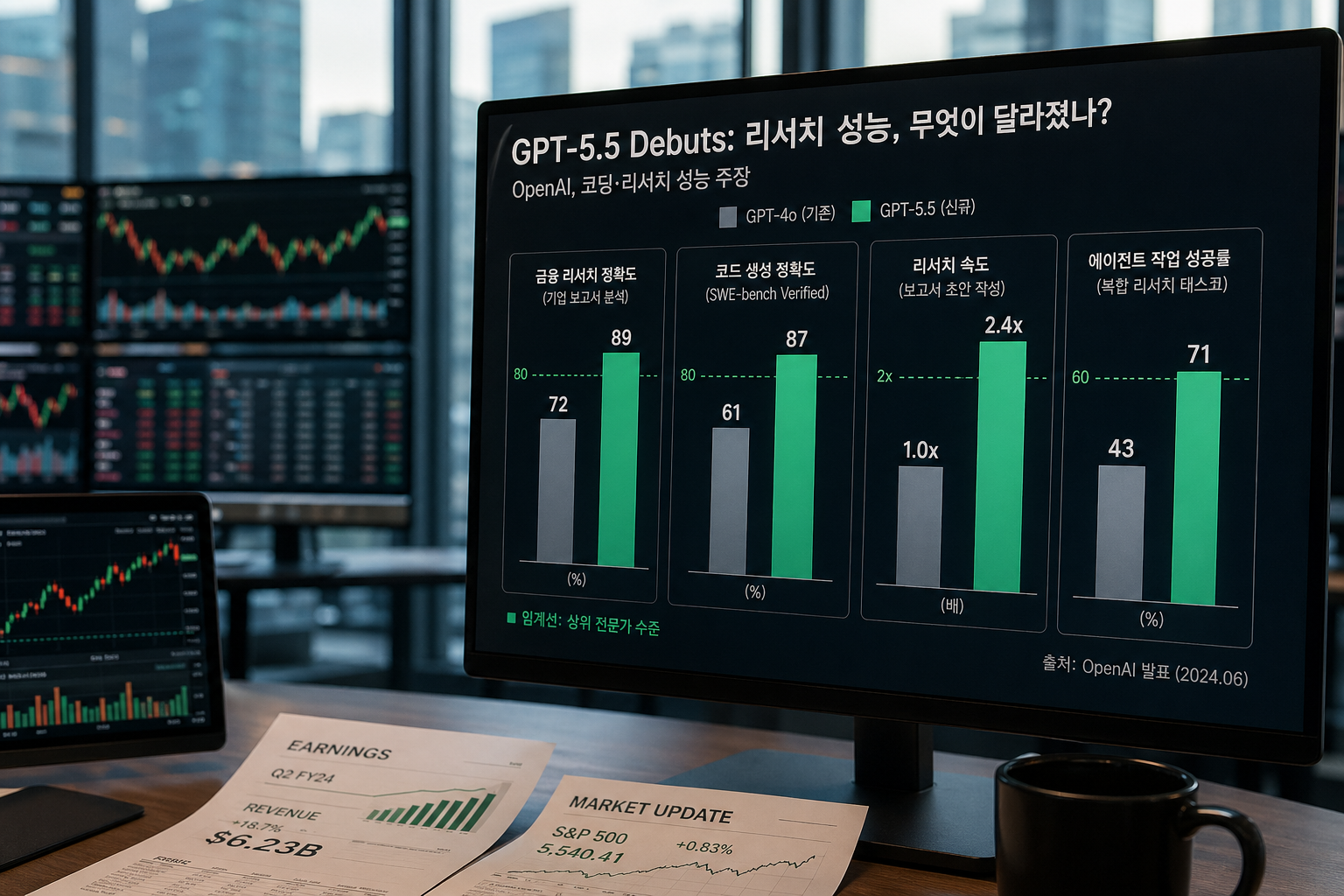
공식 평가에서 GPT-5.5는 Terminal-Bench 2.0 82.7%, SWE-Bench Pro Public 58.6%, Expert-SWE Internal 73.1%를 기록했습니다. GPT-5.4의 75.1%, 57.7%, 68.5%보다 높은 수치라서 코딩 작업형 벤치마크에서는 개선 신호가 분명합니다.
다만 모든 수치가 같은 의미는 아닙니다. Terminal-Bench 2.0은 복잡한 CLI workflow, SWE-Bench Pro는 GitHub 이슈 해결, GDPval은 지식 업무 결과물에 가깝습니다. 내 업무가 이 셋과 멀다면 “벤치마크가 높다”만으로 바로 전환할 이유는 약합니다.
그래서 다음에는 누가 지금 써야 하나를 보면 판단이 더 쉬워집니다.
누가 지금 써야 하나
먼저 체감할 사람은 Codex를 실제 작업 환경에 넣어 둔 개발자와 팀입니다. 대형 저장소에서 실패 원인을 찾고, 테스트를 돌리고, 주변 파일까지 맞춰 고치는 작업이 많다면 GPT-5.5의 긴 작업 지속성이 바로 가치가 됩니다.
두 번째는 리서치와 문서 자동화를 운영하는 실무자입니다. 자료 조사, 요약, 표 작성, 문서 생성이 한 번에 이어지는 업무 흐름이라면 컴퓨터 사용과 지식 업무 개선이 의미가 있습니다. 반면 짧은 챗봇 응답이나 가벼운 아이디어 정리만 한다면 당장 바꿀 이유는 약합니다.
마지막에는 지금 행동할지, 기다릴지, 무시해도 되는지로 정리합니다.
지금 쓰기 / 기다리기 / 무시하기
확인된 사실 / 해석 / 미확정
| 구분 | 내용 |
|---|---|
| 확인된 사실 | On April 23 and 24, 2026, OpenAI announced the release of GPT-5.5, a fully retrained base model designed for agentic workflows where it can autonomously plan, use tools, and verify its own output. |
| 작성자 해석 | 작성자 해석은 발표 문구보다 독자 의사결정에 영향을 주는 변화에 집중합니다. |
| 미확정 항목 | 실제 비용 절감률, 성능 개선 폭, 내부 배치 범위는 추가 확인이 필요합니다. |
| 업데이트 조건 | 공식 성능 사례, 가격 조건, 실제 배포 범위가 공개되면 업데이트합니다. |
깊게 볼 질문
| 질문 | 왜 중요한가 |
|---|---|
| 이 발표에서 확인된 사실은 무엇인가 | On April 23 and 24, 2026, OpenAI announced the release of GPT-5.5, a fully retrained base model designed for agentic workflows where it can autonomously plan, use tools, and verify its own output. |
| GPT-5.5 공개: 코딩·리서치 성능 주장, 지금 볼 판단 기준가 실무 판단을 바꾸는 지점은 어디인가 | 가격, 성능, 접근 권한, 운영 비용 중 실제 의사결정 변수를 분리해야 합니다. |
| 아직 단정하면 안 되는 부분은 무엇인가 | 공식 수치가 없는 비용 절감률, 내부 배치 범위, 실제 사용자 체감 변화는 미확정으로 남깁니다. |
Fluxaivory 분석 프레임
단순 발표 요약이 아니라, 실무자가 바로 점검할 수 있는 기준으로 다시 나눴습니다.
| 점검 항목 | 확인 방법 |
|---|---|
| 독자가 바로 확인할 숫자 | 가격, 성능, 출시일, 접근 권한 중 실제 결정을 바꾸는 값을 본다 |
| 업무에 닿는 장면 | 개인 사용자, 개발자, 운영팀, 구매 담당자 중 누가 먼저 영향을 받는지 나눈다 |
| 도입/보류 조건 | 지금 움직일 조건과 더 기다릴 조건을 한 표에 분리한다 |
결론
- 지금 쓰기: Codex에서 긴 코드베이스 작업, 반복 디버깅, 리서치 자동화를 이미 운영하고 있다.
- 기다리기: API 비용 상한이 중요하거나 출력 토큰이 많은 자동화를 대량으로 돌린다.
- 무시해도 됨: 짧은 질문, 단순 요약, 가벼운 글쓰기처럼 GPT-5.4급 모델로도 충분한 작업이 대부분이다.
지금 확인할 3가지
- 내 사용 경로가 ChatGPT, Codex, API 중 어디인지 먼저 구분한다.
- 출력 토큰이 긴 작업이면 100만 토큰당 30달러 기준으로 월 비용을 계산한다.
- 내 업무가 Terminal-Bench 2.0, SWE-Bench Pro, GDPval 중 어떤 평가와 가장 가까운지 확인한다.
원문 확인 링크
- https://notebooklm.google.com/notebook/01697882-ddc9-42f0-8e45-f2c99a8f3b5e#source=f4b0e300-0b0f-4831-bf1a-3d861f871a37
- https://notebooklm.google.com/notebook/01697882-ddc9-42f0-8e45-f2c99a8f3b5e#source=98d9ebab-e34b-40b5-91b2-d1c4fdda4cda
- https://notebooklm.google.com/notebook/01697882-ddc9-42f0-8e45-f2c99a8f3b5e#source=baa4d77c-fcd7-4e5e-ac74-52a59802f057
- https://notebooklm.google.com/notebook/01697882-ddc9-42f0-8e45-f2c99a8f3b5e#source=22ec9ee7-b512-486e-a984-c7327d2b6b35
- https://notebooklm.google.com/notebook/01697882-ddc9-42f0-8e45-f2c99a8f3b5e#source=7c924920-f892-41c5-809e-83ffe7c31fe4
지금 확인할 체크리스트
- 현재 배포된 AI 에이전트 목록과 권한 범위를 확인한다.
- 에이전트가 실패했을 때 중단, 되돌리기, 책임자 호출이 가능한지 본다.
- 감사 시간이 실제로 줄었는지 늘었는지 운영 로그로 비교한다.


전문가 코멘트 기준
이 글은 별도 인터뷰를 진행한 것처럼 쓰지 않습니다. 전문가·업계 관계자 발언은 공개 출처에서 확인 가능한 경우에만 인용하고, 없으면 공식 발표와 독립 보도를 기준으로 해석합니다.