
RTX Spark는 NVIDIA가 Windows 노트북과 소형 데스크톱에 넣겠다고 공개한 개인 AI 에이전트·게임용 슈퍼칩입니다. 이 변화가 실무자가 신경 쓰는 이유는 고성능 게임과 AI 에이전트 작업을 클라우드가 아니라 로컬 Windows PC에서 처리하는 흐름으로 이어질 수 있기 때문입니다. 게이머, PC방 운영자, 게임 개발사와 AI PC 제품 담당자는 실제 탑재 모델·가격·지원 게임을 먼저 판단해야 하고, DGX Spark는 개발자 책상 위에서 대형 모델 실험과 에이전트 안정성 검증을 돌리는 장비로 따로 봐야 합니다.
RTX Spark와 DGX Spark는 무엇인가
RTX Spark는 NVIDIA가 개인 AI 에이전트 시대의 Windows PC를 겨냥해 공개한 슈퍼칩입니다. 공식 발표 기준으로 1 petaFLOP급 AI 성능, 최대 128GB 통합 메모리, CUDA·RTX 생태계를 앞세워 로컬에서 AI 모델·창작 도구·게임을 함께 처리하는 노트북과 소형 데스크톱을 만들겠다는 방향입니다.
DGX Spark는 소비자용 노트북 칩이라기보다 개발자 책상 위의 AI 개발 장비에 가깝습니다. NVIDIA GB10 Grace Blackwell 계열, FP4 AI 성능, 128GB 메모리, 사전 설치된 AI 소프트웨어 스택을 기반으로 추론 모델 실험과 자율 에이전트의 프로토타입·튜닝·배포 검증에 초점이 있습니다.
| 구분 | 쉽게 말하면 | 핵심 스펙 신호 | 먼저 볼 조건 |
|---|---|---|---|
| RTX Spark | AI 에이전트·창작·게임을 로컬 Windows PC로 끌어오는 슈퍼칩 | 1 petaFLOP급 AI 성능, 최대 128GB 통합 메모리, CUDA·RTX | 탑재 노트북·소형 PC, 가격, 배터리, 지원 게임 |
| DGX Spark | 에이전트를 데스크톱에서 개발·검증하는 AI 장비 | GB10 Grace Blackwell, FP4, 128GB 메모리 | 모델 크기, 메모리, 소프트웨어 스택, 개발 워크플로우 |
핵심 요약
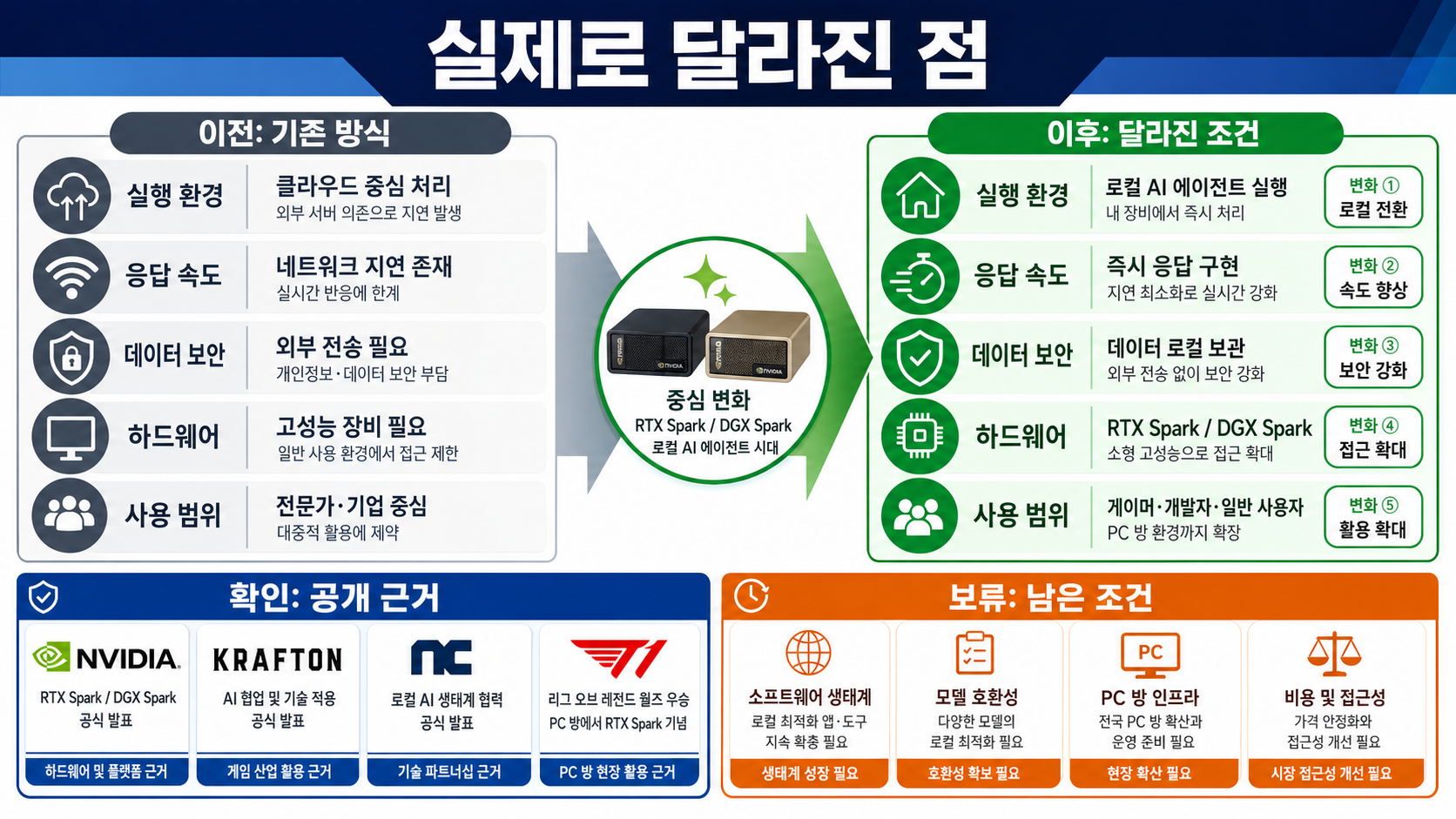
무엇이 바뀌었나
RTX Spark가 PC방과 게임사 데모를 통해 로컬 AI PC의 실제 사용 장면으로 제시됐습니다.
왜 지금 중요한가
AI 에이전트와 고성능 게임을 로컬 PC에서 처리하려면 칩 성능뿐 아니라 OEM 모델, 전력, 가격, 지원 게임 조건이 함께 맞아야 합니다.
누가 먼저 체감하나
게이머, PC방 운영자, 게임 개발사, AI PC 제품 담당자가 먼저 영향을 받습니다.
NVIDIA 공식 자료 기준으로 RTX Spark가 개인 AI 에이전트용 Windows PC를 겨냥한 슈퍼칩이라는 점과 한국 PC방 현장 공개는 확인됩니다. 다만 DGX Spark 같은 개발자용 데스크톱 장비와 같은 제품으로 섞어 읽지 말고, 출시 모델·가격·지원 게임 조건을 따로 확인해야 합니다.
이번 이슈의 관전 포인트는 RTX Spark가 무엇인지, DGX Spark와 무엇이 다른지, 그리고 PC방 데모가 실제 제품 출시와 지원 게임 조건으로 이어지는지를 나눠 보는 일입니다. 데모는 방향을 보여주지만 가격, 모델, 보급 조건이 확인돼야 판단이 강해집니다.
실제로 달라진 점
실제로 달라진 지점은 RTX Spark가 칩 발표에 그치지 않고 한국 PC방, 게임사, e스포츠 팬 접점에서 공개됐다는 점입니다. 하지만 변화의 크기는 현장 이벤트보다 실제 탑재 PC, 지원 게임, 가격, 보급 조건이 확인될 때 판단할 수 있습니다.
확인과 미확인: 지금 검증 상태
관전 포인트는 이미 확인된 사실과 아직 기다려야 할 신호를 분리하는 일입니다. 이 경계가 잡혀야 발표를 그대로 받아들이지 않고, 실제 행동으로 옮길 수 있는 범위만 남습니다.
| 구분 | 현재 판단 |
|---|---|
| 확인된 사실 | NVIDIA RTX Spark의 공개 자료가 연결된 변화만 확인된 사실로 둡니다. |
| 현재 해석 | 방향성 신호로 보되 적용 범위와 비용 조건은 따로 봅니다. |
| 미확정 항목 | 지원 범위, 요금, TCO, 호환성, 장기 운영은 독립 검증 전까지 보류합니다. |
지금 확인해야 하는 이유
- RTX Spark의 의미는 PC방 이벤트보다 개인 AI 에이전트용 Windows PC가 실제 소비자·게임 생태계에 들어오는지입니다.
- KRAFTON·NC·T1 공개는 현장 관심을 만들지만, 구매 판단은 출시 모델·가격·전력·지원 게임 조건이 나올 때 강해집니다.
- DGX Spark와 RTX Spark를 같은 제품처럼 읽으면 개발 장비와 소비자 AI PC의 판단 기준이 섞입니다.
먼저 영향을 받는 쪽
가장 먼저 볼 쪽은 게이머, PC방 운영자, 게임 개발사, AI PC 제품팀입니다. 게이머는 실제 지원 게임과 프레임 조건을 보고, 운영자는 좌석당 비용과 전력·발열 조건을 보며, 제품팀은 RTX Spark와 DGX Spark를 서로 다른 구매·개발 시나리오로 나눠야 합니다.
실제 적용 예시
예를 들어 게이머가 이 발표를 바로 구매 신호로 읽으려면 먼저 RTX Spark 탑재 노트북·소형 PC의 실제 출시 모델, 가격, 국내 공급 시점, 지원 게임 목록을 확인해야 합니다.
가령 PC방 사업자가 관심을 갖는다면 데모 장면보다 전력, 발열, 좌석당 비용, 유지보수 조건이 기존 RTX 데스크톱 구성보다 유리한지 따져야 합니다.
커뮤니티 반응은 어디서 갈렸나
한국 게이밍 커뮤니티에서 젠슨 황의 T1 PC방 방문과 RTX Spark 이벤트가 큰 화제. LoL 팬들과 게이머들의 긍정적 반응이 주를 이루며, AI PC 시대에 대한 기대와 함께 가격/접근성 우려가 섞임. 이 초기 반응은 사실 판정이 아니라, 공급 일정·비용·의존도 같은 쟁점을 어디부터 확인할지 알려주는 보조 신호입니다. 실무적으로는 기대 반응보다 실제 운영 비용, 개인정보 보호, 사람 상담원 전환 조건, 브랜드별 적용 범위를 우선 확인합니다.
| 표면 | 관측된 반응 | 읽는 법 |
|---|---|---|
| Ruliweb | 황 CEO 방문에 열광, RTX Spark 데모와 선물 이벤트 호응 | excitement |
| X (Korean users) | CINDER CITY 데모와 Krafton/NC 협력 언급, 현장 열기 공유 | positive buzz |
| FMKorea | 성공 기대감 표현 | optimism |
| RTX Spark 가격 | 고가 우려와 일반 유저 접근성 논의 | skepticism |
바로잡아야 할 오해
- RTX Spark가 즉시 모든 PC를 교체할 것
- PC방에 바로 대량 도입될 것
- 모든 게임이 완벽 지원된다고 오해
지금 판단 기준
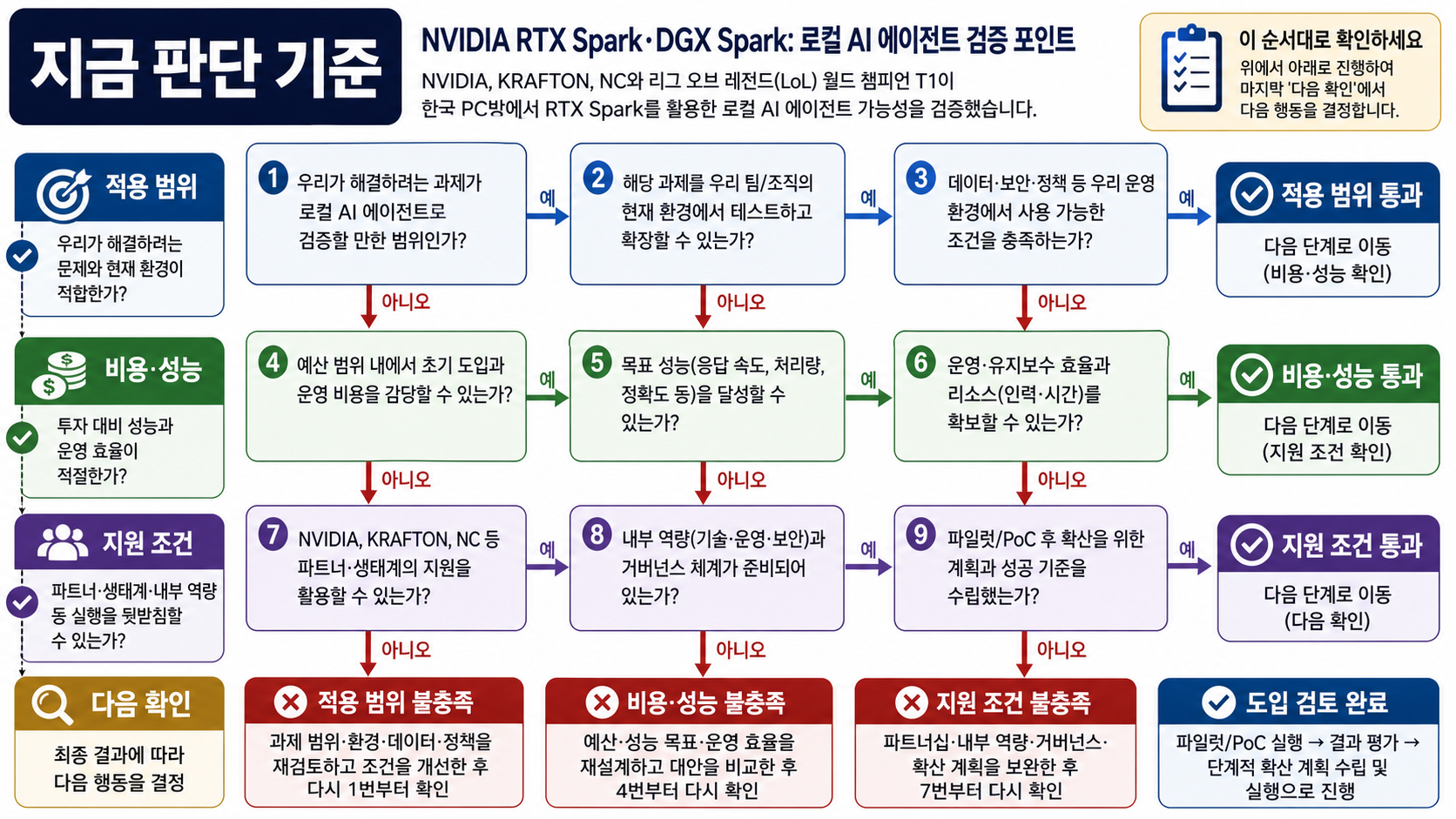
| 확인할 질문 | 지금 답 | 바로 할 일 | 기다릴 신호 |
|---|---|---|---|
| NVIDIA·한국 AI 협력의 실제 적용 범위 | NVIDIA 공식 자료 · inven.co.kr | 내 지역·기기·계정 조건에 바로 걸리는지 본다 | 요금과 출시 지역 |
- 이럴 때 움직입니다: 공식 출처와 독립 출처가 같은 방향을 가리킬 때만 실행 결정을 앞당깁니다.
결론: 지금 써볼지 말지 판단 기준
다음에 볼 항목은 RTX Spark 탑재 모델, 국내 가격, 지원 게임, OEM 공급 일정, PC방 전력·냉각 조건, DGX Spark와의 용도 차이입니다. 내 사용 시나리오가 게임·창작·로컬 에이전트라면 RTX Spark 쪽을, 개발·튜닝·장기 에이전트 검증이라면 DGX Spark 쪽을 따로 봅니다. 핵심 조건이 비어 있으면 지금은 판단을 보류합니다.
마지막 체크리스트: 지금 판단 전에 남길 질문
- 발표 주체의 원문이 핵심 주장과 직접 이어지는가.
- 금액·날짜·규제 조건처럼 결정에 영향을 주는 항목이 공개 출처에 남아 있는가.
- 뉴스·분석 출처가 원문을 확장 해석한 부분과 공식 사실이 분리돼 있는가.
- 실제 사용 가능 시점, 지원 지역, 대상 제품이 내 환경과 맞는가.
- 효과 주장과 운영 조건이 원문 기준인지 외부 해석인지 구분되는가.
아직 보류할 조건
- 후속 공시, 공식 FAQ, 규제 문서, 제품 문서가 업데이트되면 현재 판단을 다시 확인합니다.
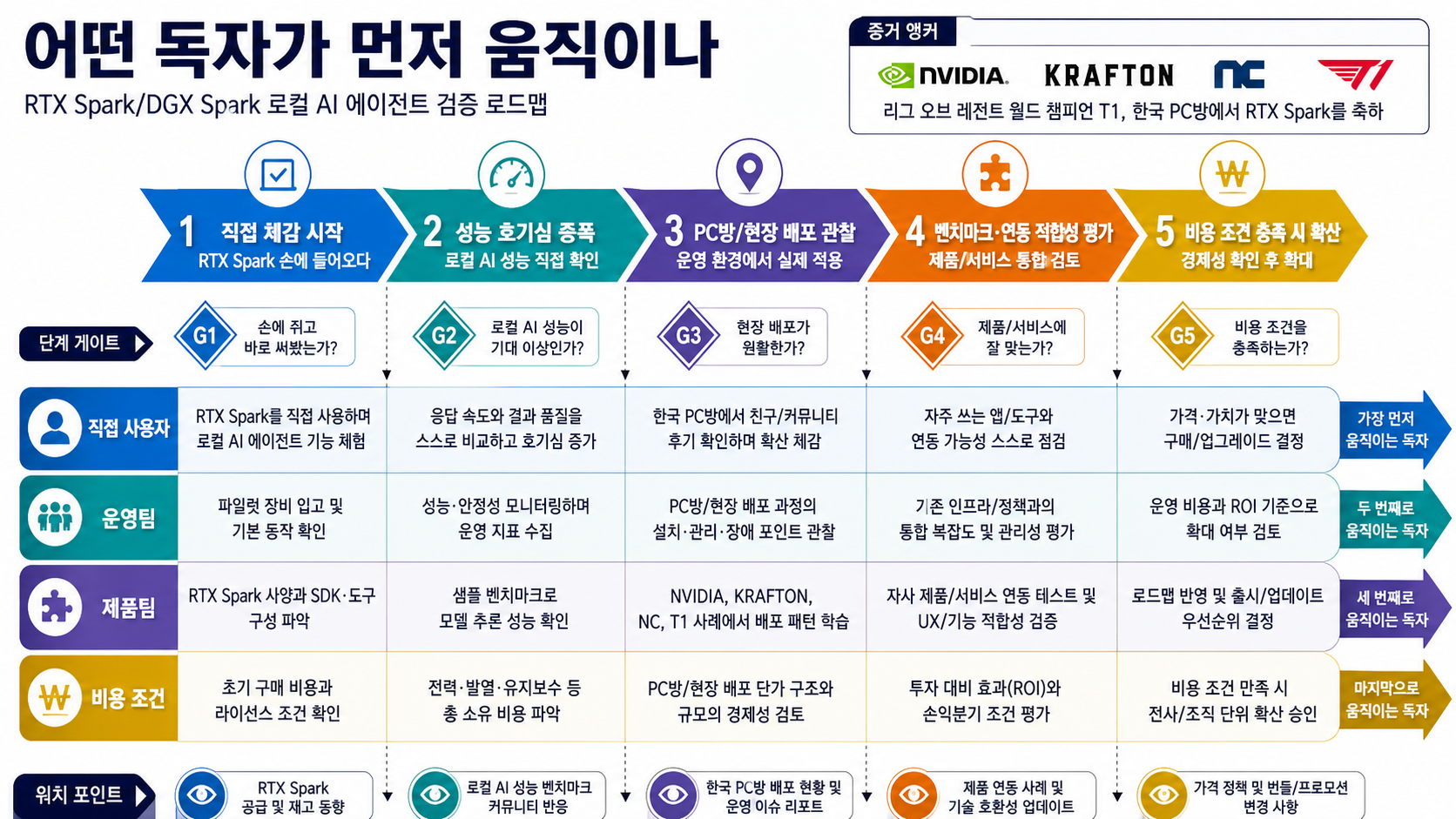
확인에 사용한 공개 출처
공식 출처
- 공개 출처 RTX Spark Legends…
- blogs.nvidia.com · Seoul Purpose: How NVIDIA and South Korea Are Building the Future of AI
추가 공개 출처
- inven.co.kr · [발표] 엔비디아, RTX PC·DGX 스파크서 로컬 AI 에이전트 기능 강화 – 인벤
- bloter.net · 젠슨 황, PC방서 게이머에게 RTX 5090·스파크 쐈다[현장+] | – 블로터
- v.daum.net · 엔비디아, AI PC 플랫폼 ‘RTX 스파크’ 발표 "전성비부터 게임까지 다 잡아" – Daum
- 공개 출처 chief bolsters ties with Krafton, NC in Seoul – The Korea Herald
- buynowkey.com · 엔비디아 Windows PC 칩 데뷔: 성능 분석 – Buy Now Key

